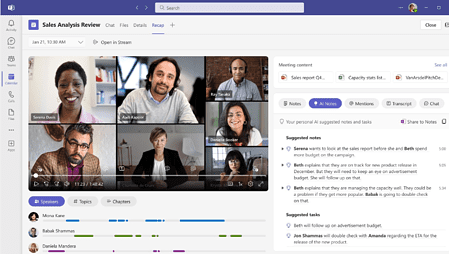
Alles wat er is te vinden overtag: GPT-3.

Topartikel
‘ChatGPT gebaseerd op illegale sites, privégegevens en piraterij’
De Nederlandse datasets om taalmodellen te trainen worden voor het grootste deel gevoed door een illegaal bev...