Meest recente uitbreiding op MySQL HeatWave moet voor goed presterende en schaalbare ML-mogelijkheden zorgen binnen de MySQL-database.
Oracle heeft als missie om van de Oracle (Autonomous) Database de enige database te maken die je nodig hebt. Althans, dat is onze interpretatie van de gang van zaken bij het bedrijf. Vorige maand kwam het nog met de Oracle Database API, waarmee het onder andere mogelijk is om MongDB JSON-databases te koppelen aan de eigen Autonomous Database. Hiermee kun je vanuit de Oracle-omgeving rechtstreeks aan de slag met de JSON-database.
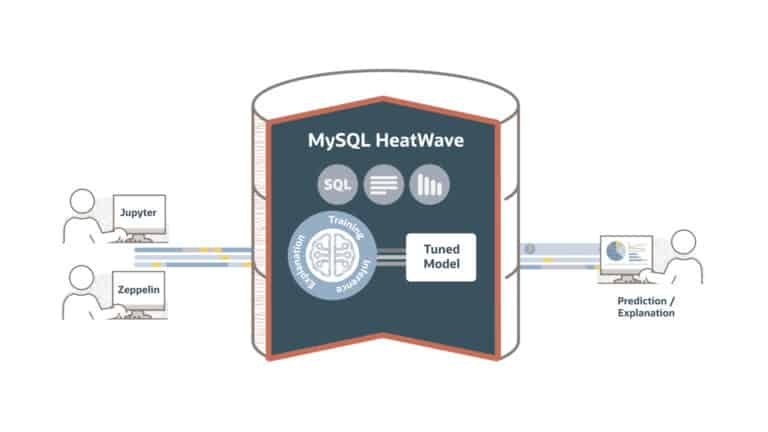
De aankondiging van vandaag kun je in principe onder hetzelfde kopje plaatsen. Met de introductie van MySQL HeatWave ML haalt Oracle namelijk machine learning de database in. Dit is potentieel erg interessant, want tot nu toe moest je voor dit soort taken data migreren tussen databases. Met andere woorden, je moest een zekere mate van ETL doen. Dat kost tijd en resources. HeatWave ML moet de volledige ML-lifecycle automatiseren en ook alle modellen in de MySQL database opslaan. Je hoeft deze dus niet meer te verplaatsen naar een specifieke ML-tool of -dienst.
MySQL HeatWave ML profiteert van ruim 10 jaar ontwikkeling
Om nog iets beter te snappen wat Oracle met MySQL HeatWave ML wil bieden, is het goed om kort even naar MySQL HeatWave zelf te kijken. Daar is deze nieuwe dienst immers onderdeel van. HeatWave is een zogeheten query accelerator. Zoals die term al aangeeft, is het doel van HeatWave om MySQL-queries sneller te laten verlopen. Het is ook onderdeel van de MySQL-database, die van origine is ontworpen voor transactionele doeleinden, niet per se voor de hoogste prestaties op het gebied van de queries zelf. Vandaar dat gebruikers voor zaken als de beste prestaties en schaalbaarheid vaak meerdere databases naast elkaar gebruiken. En dus ook veel data tussen databases moeten migreren. Als MySQL HeatWave doet wat het belooft, is dat nu niet meer nodig.
Een query accelerator toevoegen aan een transactionele MySQL-database klinkt wellicht niet zo ingewikkeld. Oracle heeft echter meer dan tien jaar aan MySQL HeatWave gewerkt. Het is dus in ieder geval een stevige klus geweest. Het doel was dan ook om MySQL HeatWave massively parallel en massively partitioned te maken. Dat zijn de twee voorwaarden om zowel uitstekende prestaties als schaalbaarheid te kunnen bieden. Data wordt eerst in partities verdeeld, die vervolgens parallel aan elkaar worden verwerkt. Aan het einde voegt HeatWave de partities weer samen. Hieronder zie je hoe dat schematisch in elkaar zit.

Hoge prestaties = hoge kosten?
Hoge prestaties hebben vaak ook hoge kosten als keerzijde. Oracle claimt dat dit met MySQL HeatWave niet het geval is. Deze dienst is naar eigen zeggen geoptimaliseerd voor commodity clouddiensten en de voordeligste opties op het gebied van compute, storage en network. Denk hierbij aan object storage in plaats van duurdere vormen van opslag, of AMD-cpu’s in plaats van processors van Intel.
Oracle mag MySQL HeatWave dan hebben ontwikkeld voor hoge prestaties in combinatie met een relatief lage prijs, voor klanten is het doorgaans nooit voordelig genoeg. Dat was dan ook de feedback die Oracle vanuit haar klanten kreeg. Deze waren blij met de forse prestatieverbeteringen ten opzichte van bijvoorbeeld Snowflake en AWS Redshift, maar vonden MySQL nog altijd niet echt goedkoop. Om hieraan tegemoet te komen, heeft Oracle nog wat verdere optimalisaties doorgevoerd. Het is vanaf nu mogelijk om twee keer zoveel data als voorheen per node te verwerken. Dit zou weer een stevige hap uit het kostenplaatje moeten nemen. Deze verdubbeling is mogelijk dankzij datacompressie.
Als het gaat om kosten, is er ten slotte nog een interessante toevoeging aan Oracle MySQL HeatWave. Vanaf nu is het ook mogelijk om HeatWave te pauzeren als je het even niet wilt gebruiken. Wil je na verloop van tijd toch weer gebruikmaken van de dienst, dan laadt het data en statistieken automatisch weer in.
Realtime elasticity
Een laatste nieuwtje op het gebied van MySQL HeatWave is wat Oracle real-time elasticity noemt. De feedback van klanten was dat het op zich erg fijn is dat HeatWave heel goed schaalt, maar dat ze hun HeatWave-cluster nog wel handmatig moesten resizen. Dat houdt ook in dat er dan sprake is van downtime, en dat is in principe nooit wenselijk. Real-time elasticity neemt dit probleem weg. Je hoeft vanaf nu niet meer handmatig aan de slag om het HeatWave-cluster na resizen weer handmatig te optimaliseren.
Zowel MySQL HeatWave ML als de andere drie nieuwe features die we in dit artikel hebben besproken zijn vanaf vandaag beschikbaar voor alle afnemers van MySQL HeatWave in alle OCI-regio’s.