Alleen een moderne storage infrastructuur is niet meer voldoende tegenwoordig. Data moet steeds eenvoudiger beschikbaar zijn en het moet ook steeds sneller gebeuren. Pure Storage speelt met enkele aankondigingen die het vandaag doet in op deze evolutie. Wij spraken hierover met Marco Bal, Principal Systems Engineer bij Pure.
Pure Storage heeft zich sinds de oprichting in 2009 vooral gericht op het ontwikkelen en aanbieden van een zo geavanceerd en modern mogelijke infrastructuur. De nadruk op all-flash in de FlashArray-systemen heeft hier een belangrijke rol in gespeeld uiteraard. Maar denk bijvoorbeeld ook aan het aanbieden van UFFO, oftewel Unified Fast File and Object-opslag, met FlashBlade. Het beschikbaar maken van flash voor storage in lagere tiers (met FlashArray//C) is eveneens een voorbeeld van deze ontwikkeling.
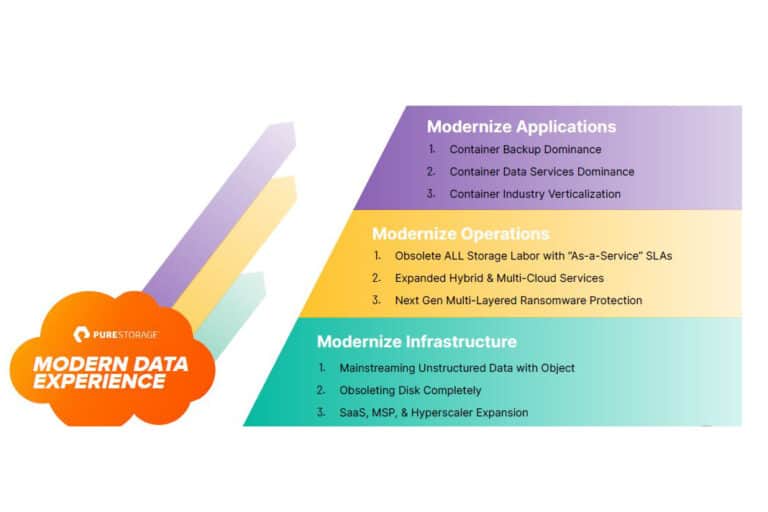
Met alleen infrastructuur ben je er tegenwoordig echter niet meer. Je moet er ook steeds meer voor zorgen dat je de data goed beschikbaar kunt maken. Dat betekent onder andere het moderniseren van operations, waarbij je cloud-functionaliteit on-prem beschikbaar maakt. Het idee is dat gebruikers storage willen consumeren en verder geen gedoe, vat Bal het samen. Kernwoorden en -begrippen hiervoor zijn zichtbaarheid, schaalbaarheid, directe beschikbaarheid, intelligente workloads en een SLA-benadering zoals we die kennen uit de cloud.
Pure Fusion
Om alle kernwoorden en -begrippen hierboven af te kunnen dekken, introduceert Pure vandaag Pure Fusion. Deze nieuwe (SaaS-)dienst moet “storage-as-code op een ongelimiteerde schaal” mogelijk maken, geeft Bal aan. Het is een vrijwel volledig autonoom opererende laag bovenop je infrastructuur. Deze moet het mogelijk maken om oneindig te kunnen schalen. Er wordt hierbij ook slim omgegaan met de beschikbare opslag in de fysieke FlashArrays (en FlashBlades) en met de workloads die er gebruik van maken. Met andere woorden, de fysieke grenzen van een enkel array zijn in principe geen probleem bij het opschalen. Alles wordt immers verdeeld over alle beschikbare arrays.

Belangrijk bij Pure Fusion is ook de koppeling met Pure1, het AIOps-platform van Pure Storage. Tot nu toe kon je dit vooral inzetten voor het monitoren van je omgeving. In combinatie met Pure Fusion kun je het gebruiken om onder andere de storage class te definiëren van specifieke data. Op basis van die storage class, bepaalt Fusion waar de data opgeslagen moet worden. Is er snelle storage nodig, dan kiest het beheerplatform voor //X-arrays. Is het data voor een applicatie die nog in ontwikkeling is, dan kan het ook prima op een //C-array. Je kunt deze classificatie overigens nadien ook aanpassen. Dit is vaak handig als je een applicatie daadwerkelijk in productie neemt en je snellere opslag nodig hebt.
Het opschalen van je zogeheten vloot aan arrays gebeurt binnen Pure Fusion ook allemaal achter de schermen. Je kunt arrays toevoegen, zaken verplaatsen en balanceren zonder dat je daar aan de voorkant iets van merkt. Pure gebruikt hier onder andere de ActiveCluster synchrone replicatietechnologie voor. Voor de bescherming van de data maakt Fusion gebruik van policies. Tot slot is het ook mogelijk om te forecasten, om zo allerlei (support) tickets voor te zijn. Als een array in korte tijd bijvoorbeeld al halfvol is, dan zal Fusion daar op gepaste manier op inspringen.

Portworx Data Services
Eerder dit jaar zijn we al even ingegaan op de eerste integraties van het vorig jaar door Pure overgenomen Portworx met het Pure-platform. Met deze overname zet Pure een duidelijke stap richting de ondersteuning van (hybride) cloudomgevingen. In tegenstelling tot eerdere overnames zoals Compuverde, lijkt Portworx vooralsnog als op zichzelf staand onderdeel van Pure door te gaan. Het wordt dus niet volledig geïntegreerd in het bestaande aanbod. Dit geeft ook meteen aan dat Portworx actief is in een gebied dat je echt als nieuw terrein voor Pure zou kunnen omschrijven. Het is dus overduidelijk een stap in de breedte, geen verdieping van het bestaande aanbod, zoals bij Compuverde wel het geval was.
Het Portworx Enterprise-platform is een storage en datamanagement oplossing specifiek gericht op Kubernetes-projecten. Het gaat hier dan met name om het opzetten van de data services die je vervolgens weer koppelt aan applicaties. Vandaag kondigt Pure Storage naast Pure Fusion ook Portworx Data Services aan. Het idee achter dit nieuwe aanbod is dat je met een enkele click dataservices op Kubernetes uit kunt rollen. Daarbij gaat het niet alleen om de storage-laag, maar ook om het beheer van de database die eraan gekoppeld is.

Het doel van Portworx Data Services is om weer wat complexiteit weg te nemen bij het inrichten van nieuwe workloads. Het biedt vrijwel geautomatiseerde DBaaS aan. Je kiest het type database of dataservice in een portal en geeft nog wat karakteristieken aan in dat portal. De rest zet Portworx Data Services op voor je. Het maakt hierbij in principe niet uit of de data afkomstig is uit Apache Kafka, Cloudera, SQL, NoSQL, Elastic, PostgreSQL, Spark of Microsft SQLServer, om maar een paar bronnen te noemen. Voor closed-source bronnen is het overigens nog niet duidelijk of je bij Pure ook licenties af kunt nemen, of dat het een BYOL-benadering wordt.
Een laatste belangrijke component van Portworx Data Services is dat Pure met templates gaat werken. Het idee is dat je dankzij deze templates niet per se een specialist hoeft te zijn om met de nieuwe dienst aan de slag te kunnen gaan. Ook ben je niet beperkt tot Pure-infrastructuur. De nieuwe dienst werkt zowel on-prem als in de cloud. Portworx Data Services is nu beschikbaar als early access.
Updates in Pure1
Naast de twee grote aankondigingen, is er ook nog nieuws rond Pure1. Zo komen er pro-actieve aanbevelingen in het platform. Dat wil zeggen, het wordt mogelijk om suggesties te doen om workloads elders te draaien als dat betere prestaties oplevert. Voorheen was dat inzicht er ook al, maar toen gaf het platform de aanbevelingen zelf niet. Dat moest je als admin zelf in de gaten houden.
Een tweede update van Pure1 richt zich op security. Met SafeMode Snapshots kun je omgevingen beter beschermen tegen met name ransomware. Binnen Pure1 brengt Pure Storage in kaart welke arrays SafeMode ingeschakeld hebben en welke niet. Ook kun je meteen zien of een array nog een update nodig heeft om SafeMode in te kunnen schakelen. De Snapshots die Pure1 maakt binnen SafeMode zijn immutable overigens. Daar kunnen kwaadwillenden niet meer bijkomen. Pure biedt hiermee geen bescherming tegen ransomware, maar zorgt er wel voor dat het niet mogelijk is om alle data te wissen of te encrypten.
Een laatste update voor Pure1 heeft wederom te maken met Portworx. Er is nu een integratie tussen deze twee onderdelen. Je kunt dit het beste zien als de containervariant op de VM Analytics-functionaliteit, die sinds 2018 deel uitmaakt van Pure1. Het doel is om hiermee vanaf de container tot aan de arrays de hele keten van applicaties inzichtelijk te maken. Hiermee kun je issues sneller opsporen en ook op het gebied van het efficiënt inzetten van je opslag de nodige inzichten krijgen.
Pure Storage schaalt (horizontaal) door
Pure claimt altijd dat het bedrijf in 2009 is opgericht met cloud management in het achterhoofd. Dat wil zeggen, FlashArray is vanaf het begin ontwikkeld met zaken zoals modulariteit en schaalbaarheid in het achterhoofd. Zelf heeft het bedrijf het nu over het ‘cloudificeren’ (cloudifying) van de infrastructuur. Met de aankondigingen van vandaag heeft het weer enkele duidelijke stappen in die richting gezet. Dat moet uiteraard ook wel, omdat klanten nu eenmaal meer eisen en wensen hebben. Alleen een extreem snelle en uitstekend beschikbare infrastructuur is niet meer voldoende. Op het vlak van operations (met Pure Fusion) en services (met Portworx Data Services) zet Pure nu behoorlijk grote stappen richting het beantwoorden van die wensen en eisen.