Ondanks alle hype zit AI met een probleem. Hoe overtuigend de vaardigheden van ChatGPT of een zelfrijdende auto al kunnen zijn, leren ze niet zomaar van hun fouten. Bij MIT ontdekte men “liquid neural networks”, die veel bestaande uitdagingen voor AI zouden kunnen oplossen. Wat houdt deze innovatie in? En welke problemen kan het oplossen waar AI tot nu toe nog tekort komt?
Een onderzoeksteam aan het fameuze MIT zag nog ver voordat ChatGPT de wereld veroverde welke problemen AI-modellen kennen. Om accuratesse te garanderen, lijken gigantische datasets een essentieel onderdeel. Daarbovenop moet die informatie goed gecontroleerd worden op onjuistheden en dient het gebalanceerd te worden om gevrijwaard te blijven van ongewenste vooroordelen. Het trainen en draaien van deze AI-modellen kost enorm veel energie, geld en hardware.

Het resultaat is er soms wel naar: veel outputs van chatbots komen aardig menselijk over, dat an sich al een hele prestatie is. Generatieve AI blijft echter veelal een black box, al helemaal omdat een partij als OpenAI niet veel vertelt over hoe het meest geavanceerde model (GPT-4) in elkaar zit. Ondanks alle rekenkundige vuurkracht hallucineren deze AI-modellen erop los. Een voorbeeld van hoe het anders kon was Dolly 2.0 van Databricks, waarmee indrukwekkende resultaten haalbaar bleken te zijn met een klein AI-model en zeer specifieke data.
Tip: Dolly 2.0: een transparant AI-alternatief voor GPT-4
Terug naar de basis
Er zijn meer AI-modellen in de rondgang dan alleen large language models, maar allen lijken te kampen met soortgelijke problemen. Zo kan een deep learning-model van bijvoorbeeld Nvidia als geen ander een 1080p-beeld slim upscalen naar 4K met overtuigende resultaten, maar heeft ook dat geen ‘weet’ van wat het doet. Daarnaast zijn AI-modellen statisch totdat ze hertraind zijn of er met de parameters gesleuteld is. Ze zijn sterk afhankelijk van labels en verfijning van de datasets, terwijl ze buiten de context van een testscenario de plank meestal misslaan.
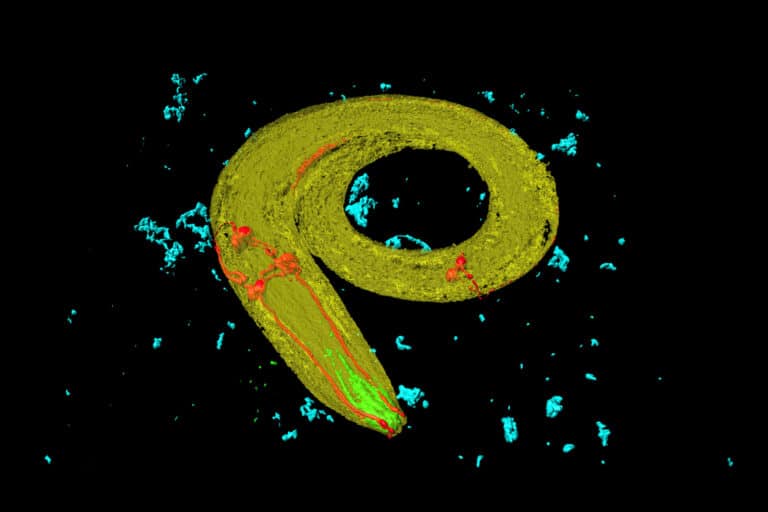
Bij MIT ging een onderzoeksteam in 2020 terug naar de basis: de inspiratie voor kunstmatige intelligentie begint bij de echte wereld. Tegenover Quanta Magazine lieten Ramin Hasani en Mathias Lechner weten dat men inspiratie haalde uit een rondworm van ongeveer een millimeter, de Caenorhabditis elegans. Als een van de weinige organismen met een volledig onderzocht zenuwstelsel is het in staat om te bewegen, te eten, zich te reproduceren en vooral: om te leren. Ze lijken goed om te gaan met veranderende omgevingen in de natuur. Dat is nou precies waar liquid neural networks, die hun ontwerp ontlenen aan deze rondworm, een sprong in de ontwikkeling van AI kunnen maken.
Het testscenario
De MIT’ers zijn al een tijdje bezig met het kenbaar maken van hun bevindingen, maar hun uitleg blijft overwegend hetzelfde. Men ontwikkelde een AI-model waarbij het aantal neuronen nog erg overzichtelijk blijft. In zijn testscenario spreekt Hasani over 19 neuronen die zich kunnen aanpassen op de output waar ze mee te maken hebben. Het team testte liquid neural networks tegenover traditionele AI-modellen in twee scenario’s: het besturen van een zelfrijdende auto op een gesloten testcircuit en het aansturen van een drone richting gekleurde objecten. Het frappante: men vertelde niet wat precies de taak was.

Bij de tests viel op dat gewone AI-modellen hoofdzaak en bijzaak niet zonder extra hulp kunnen onderscheiden. Bij de rijproef was op de heatmap van de camera te zien dat conventionele AI zich bijvoorbeeld richt op het gras langs de weg of lichtpunten tussen de bomen. De liquid neural network kijkt echter zoals een mens dat doet: het richt zich op een ver punt op de weg en houdt de randen van de weg in de gaten. Daarnaast is in de visuele representatie te zien dat het MIT-model keurig stabiel blijft bij deze observatie.

Veelbelovend maar vroeg
Liquid neural networks zijn een stuk compacter dan bijvoorbeeld een LLM als GPT-4 of LLaMA 2. Het is voor een robot, zelfrijdende auto of bezorgdrone niet denkbaar dat dergelijke grote modellen intern kunnen draaien: er is een hele vloot aan robuuste hardware voor nodig.
Daniela Rus, directeur van MIT CSAIL, vertelde VentureBeat dat de inspiratie achter liquid neural networks deels voortkwam uit het praktisch willen inzetten van AI. De compactheid van liquid neural networks zijn wat dat betreft veelbelovend.
Terwijl bedrijven momenteel elke Nvidia-chip kopen die in hun buurt komt, lijkt de AI-hype een richting te hebben gekozen. Echter is ook generatieve AI nog in de kinderschoenen en zijn de groeipijnen voelbaar. Een alternatief als dat van MIT is daarom veelbelovend, maar ook daar zal het afwachten zijn.
Een belangrijk wapenfeit ervoor is wel dat de overizchtelijkheid van de individuele neuronen het een stuk eenvoudiger zal maken om de redeneringen achter de output te vinden. Aangezien de AI Act vanuit de EU het vuur aan de schenen kan leggen van big tech, is het een goed moment om rond te kijken hoe AI overzichtelijk, betrouwbaar en werkbaar kan zijn. Liquid neural networks zijn wat dat betreft een intrigerend fenomeen. Het zal echter nog wel even duren voordat het een eventuele volgende hype-cyclus zal voeden.
Lees ook: AI Act: een wetgeving die altijd moet bijbenen met een nieuwe werkelijkheid