Een nieuwe tool van IBM maakt het voor ontwikkelaars makkelijker om data in machine learning- of objectdetectie-modellen te detecteren. Bij dit proces komt normaliter vaak handmatige training met honderden tot duizenden beelden kijken, maar met de IBM-tool gebeurt het labellen automatisch.
De nieuwe oplossing maakt onderdeel uit van de open source Cloud Annotations image toolset van IBM en gebruikt kunstmatige intelligentie (AI) om te ondersteunen bij het labeling proces. Big Blue hoopt de tool aantrekkelijk te maken voor data scientists door er een gratis tool van te maken, waardoor ze tijd kunnen besparen bij het maken van AI-toepassingen. Volgens het bedrijf zijn er bij het maken van een model momenteel namelijk 200 tot 500 samples nodig van manueel gelabelde beelden om één specifieke object te kunnen detecteren.
Werking
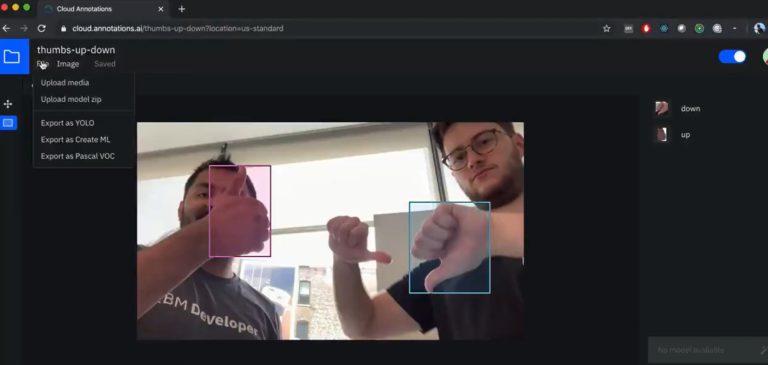
Cloud Annotations wordt dan ook omschreven als een snelle en eenvoudige open source beeld annotatie-tool. Het project is gebouwd bovenop IBM Cloud Object Storage, waarvoor een IBM Cloud-account nodig is om het te gebruiken. Hiervan wordt een gratis versie aangeboden, welke met 25 GB opslag komt. Het moet voor ontwikkelaars ook makkelijker worden om samen te werken aan het model, aangezien ze in real-time met de dataset bezig kunnen zijn.
Het is mogelijk om Cloud Annotations in te zetten voor zowel foto’s als video’s. Hiervoor moeten gebruikers een aantal voorbeeld images met labels uit het verleden uploaden in de tool en een aantal stappen doorlopen om het model te trainen. Vervolgens kunnen ze ‘Autolabel’ selecteren en beoordelen of de tool de gewenste objecten heeft gelabeld.
De tool is voor iedereen beschikbaar op GitHub.
Inspanningen
IBM is de laatste tijd actief bezig om analytics en kunstmatige intelligentie verder te ondersteunen. Onlangs kwam het bijvoorbeeld met zijn Watson Anywhere-initiatief, waarmee het een aantal data-complexiteiten weg wil halen. Zo introduceert het als onderdeel hiervan tools om data uit iedere bron toegankelijk te maken.